1、Kafka概述1.1. Kafka简介1.2. Kafka的设计目标1.3. Kafka的发展历史1.4. Kafka的常见应用场景1.5. Kafka的核心概念1.6. Kafka的核心API2、Kafka环境部署2.1. 单机版本搭建2.1.1. 下载并解压安装2.1.2. 启动服务2.1.2.1. 启动ZooKeeper2.1.2.2. 启动Kafka2.1.3. 创建主题2.1.4. 列出主题2.1.5. 发送消息2.1.6. 消费消息
1、Kafka概述
1.1. Kafka简介
- Apache Kafka是一个开源消息系统、一个开源分布式流平台,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
- Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目设计目标是为处理实时数据提供一个统一、高吞吐量、低等待的平台。
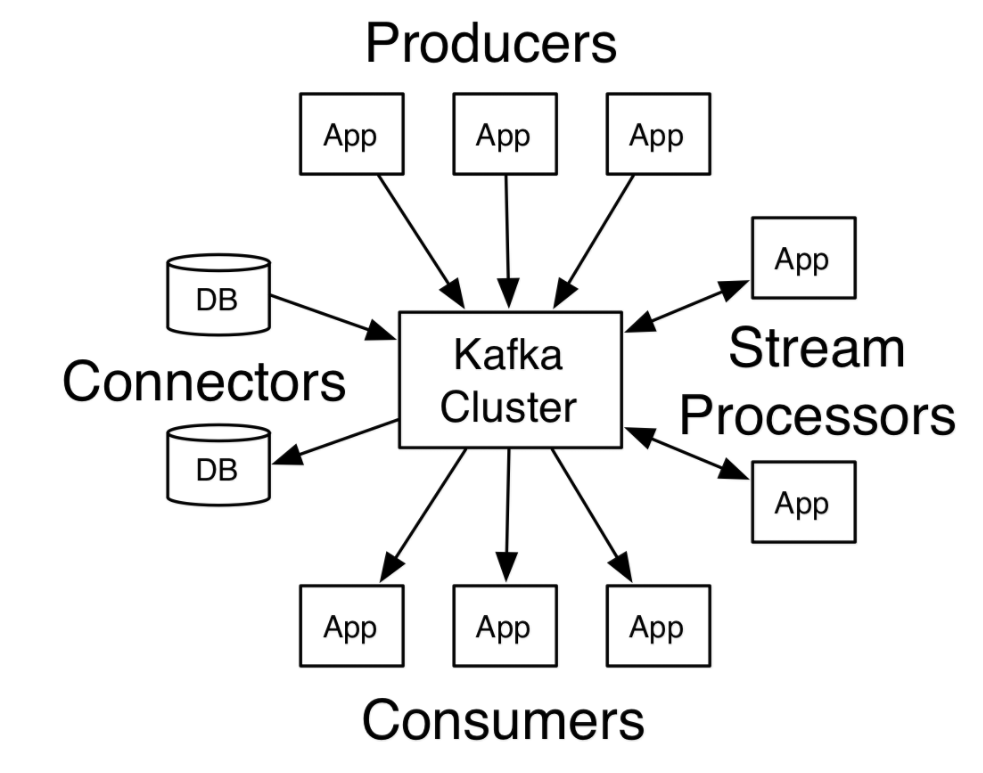
- Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
- Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
- 无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
1.2. Kafka的设计目标
- 高吞吐率 在廉价的商用机器上单机可支持每秒100万条消息的读写
- 消息持久化 所有消息均被持久化到磁盘,无消息丢失,支持消息重放
- 完全分布式 Producer,Broker,Consumer均支持水平扩展
- 同时适应在线流处理和离线批处理
1.3. Kafka的发展历史
- 2010年底,开源到github,初始版本为0.7.0;
- 2011年7月因为备受关注,kafka正式捐赠给apache进行孵化;
- 2012年10月,kafka从apache孵化器项目毕业,成为apache顶级项目;
- 2014年,jay kreps,neha narkhede,jun rao离开linkedin,成立confluent,此后linkedin和confluent成为kafka的核心贡组织,致力于将kafka推广应用;
- Kafka集成了分发、存储和计算的“流式数据平台”,不再是一个简单的分布式消息系统。
1.4. Kafka的常见应用场景
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming、flink和storm等整合应用。
1.5. Kafka的核心概念

如图中,红色方框里面的都是kafka相对较核心概念,具体阐述如下:
Broker(代理):Kafka 节点,一个 Kafka 节点就是一个 broker,多个 broker 可以组成一个 Kafka 集群,每一个broker可以有多个topic。
Producer(生产者): 生产 message (数据)发送到 topic。
Consumer(消费者):订阅 topic 消费 message,consumer 作为一个线程来消费。
Consumer Group(消费组):一个 Consumer Group 包含多个 consumer,这个是预先在配置文件中配置好的。
Topic(主题):一种类别,每一条发送到kafka集群的消息都可以有一个类别,这个类别叫做topic,不同的消息会进行分开存储,如果topic很大,可以分布到多个broker上,例如 page view 日志、click 日志等都可以以 topic的形式存在,Kafka 集群能够同时负责多个 topic 的分发。也可以这样理解:topic被认为是一个队列,每一条消息都必须指定它的topic,可以说我们需要明确把消息放入哪一个队列。
Partition(分区):topic 物理上的分组,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
Replicas(副本):每一个分区,根据副本因子N,会有N个副本。比如在broker1上有一个topic,分区为topic-1, 副本因子为2,那么在两个broker的数据目录里,就都有一个topic-1,其中一个是leader,一个replicas。
Segment:partition 物理上由多个 segment 组成,每个 Segment 存着 message 信息。
1.6. Kafka的核心API
The Producer API allows an application to publish streams of records to one or more Kafka topics.
Producer API(生产者API)允许一个应用程序去推送流式记录到一个或者多个kafka的topic中。
The Consumer API allows applications to read streams of data from topics in the Kafka cluster.
Consumer API(消费者API)允许一个应用程序去订阅消费一个或者多个主题,并处理生产给他们的流式记录。
The Streams API allows transforming streams of data from input topics to output topics.
Streams API允许将数据流从输入主题转换为输出主题。
The Connect API allows implementing connectors that continually pull from some source data system into Kafka or push from Kafka into some sink data system.
Connect API允许实现连接器,这些连接器可以持续地从某个数据源中拉取数据到Kafka,或将数据从Kafka推入某个接收的数据系统。
The Admin API supports managing and inspecting topics, brokers, acls, and other Kafka objects.
Admin API支持管理和检查主题、代理、ACL和其他Kafka对象。
2、Kafka环境部署
2.1. 单机版本搭建
单机版本的搭建最为快速、简单,但是使用场景非常局限。仅适用于进行简单的测试阶段。
强烈建议安装多Broker的集群版本!
2.1.1. 下载并解压安装
下载地址:http://archive.apache.org/dist/kafka/2.4.1/kafka_2.12-2.4.1.tgz
注:
安装包的命名中,2.12表示Scala的版本。由于Kafka是使用Scala语言来编写的,因此在下载Kafka的时候,会让你选择Scala语言的版本。你只需要选择与你本地的Scala版本相符的Kafka即可。
# 将下载好的Kafka的安装包上传到/root/software目录下# 进入到/root/software目录下,解压安装[root@qianfeng01 ~]$ cd /root/software[root@qianfeng01 software]$ tar -zxvf kafka_2.12_2.4.1.tgz -C /usr/local2.1.2. 启动服务
2.1.2.1. 启动ZooKeeper
Kafka严重依赖ZooKeeper,所以我们在启动Kafka之前,需要启动ZooKeeper服务。Kafka提供给咱们快速使用的zk服务,即解压开压缩包,其根目录下的bin目录下提供zk的启停服务,但仅适用于单机模式(zk也是单实例)。多broker模式强烈建议使用自行部署的ZooKeeper。
Kafka自带的ZooKeeper的启停脚本如下:

启用Kafka自带的ZooKeeper服务
xxxxxxxxxx[root@qianfeng01 kafka-2.4.1]$ cd /usr/local/kafka-2.4.1[root@qianfeng01 kafka-2.4.1]$ bin/zookeeper-server-start.sh config/zookeeper.properties &2.1.2.2. 启动Kafka
xxxxxxxxxx[root@qianfeng01 kafka-2.4.1]$ cd /usr/local/kafka-2.4.1[root@qianfeng01 kafka-2.4.1]$ bin/kafka-server-start.sh config/server.properties启动之后,可以使用jps命令查看当前节点的进程。如果出现名为kafka的进程,说明Kafka的单机版本搭建完成。
2.1.3. 创建主题
在Kafka中,消息是需要存储与主题中的,Producer会将消息写入到指定的Topic中,而消费者会从指定的Topic中读取数据。
xxxxxxxxxx# 创建一个名为test的主题[root@qianfeng01 ~]$ cd /usr/local/kafka-2.4.1[root@qianfeng01 kafka-2.4.1]$ bin/kafka-topics.sh --create \--bootstrap-server qianfeng01:9092 \--replication-factor 1 \--partitions 1 \--topic test2.1.4. 列出主题
xxxxxxxxxx# 如何知道主题创建完成了呢?可以使用下面这个命令查看所有的主题列表[root@qianfeng01 kafka-2.4.1]$ bin/kafka-topics.sh --list \--bootstrap-server qianfeng01:90922.1.5. 发送消息
Kafka自带一个命令行客户端(client),它将从文件或标准输入中获取输入,并将其作为消息发送到Kafka集群。默认情况下,每一行都将作为单独的消息发送。
运行producer,然后输入一些信息到控制台并发送到服务端:
xxxxxxxxxx[root@qianfeng01 kafka-2.4.1]$ bin/kafka-console-producer.sh \--broker-list localhost:9092 \--topic test>this is a message # 发送的第一条消息>this is anthor message # 发送的第二条消息# --broker-list是指定broker的服务器地址,默认端口是90922.1.6. 消费消息
kafka有一个消费者客户端命令,它可以转存消息到标准输出:
xxxxxxxxxx[root@qianfeng01 kafka-2.4.1]$ bin/kafka-console-consumer.sh \--bootstrap-server localhost:9092 \--topic test \--from-beginning # --bootstrap-server 指定kafkaserver地址 # --from-beginning从开始位置开始消费,默认情况使用from-beginning注意:
如果有一个producer生产消息终端,另外有多个consumer终端,那么多个consumer将会同时立即消费。
所有命令行都有更多的额外参数,可以参考文档查看更多的options。